Regardless of machine learning library you use, the data preparation is the first and one of the most important step in developing predictive models. It is very often case that the data supposed to be used for the training is dirty with lot of unnecessary columns, full of missing values, un-formatted numbers etc. Before training the data must be cleaned and properly defined in order to get good model. This is known as data preparation. The data preparation consist of cleaning the data, defining features and labels, deriving the new features from the existing data, handling missing values, scaling the data etc. It can be concluded that the total time we spend in ML modelling,the most of it is related to data preparation.
In this blog post I am going to present the simple tool which can significantly reduce the preparation time for ML. The tool simply loads the data in to GUI, and then the user can define all necessary information. Once the data is prepared user can store the data it to files which can be then directly imported into ML algorithm such as CNTK.
The following image shows the ML Data Preparation Tool main window.
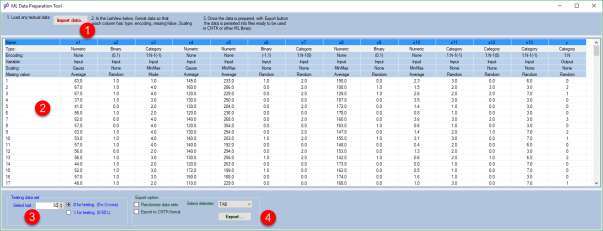
From the image above, the data preparation can be achieved in several steps.
From the image above, the data preparation can be achieved in several steps.
- Load dirty data into ML Prep Tool, by pressing Import Data button
- Transform the data by providing the flowing table:
| Column option | Suboptions | Description |
|---|---|---|
| Name | xi, y | In case the header is not provided in the imported data, automatic column names is generated. |
| Type | Numeric | Indicates the column is cominuous numeric value. |
| Binary | Idicated the column data is binary with ony two posible values e.g. (male, femail) | |
| Category | Indicates the column data is categorical with more than two values. e.g. (R,G,B) | |
| String | The column will be ignore during export. | |
| Encoding | In case of Binary and Category column type, the encoding must be defined. | |
| (0,1) | First binary values will be 0, and second binary values will be 1. | |
| (-1,1) | First binary values will be -1, and second binary values will be 1. | |
| N | Category Level where each class treats as numeric value. In case of 3 categories(R,G, B), encoding will be (0,1,2) | |
| 1:N | Category representation with One-Hot vector with N columns. In case of 3 categories(R,G, B), encoding will be R = (1,0,0),G = (0,1,0), B = (0,0,1) | |
| 1:N-1(0) | Category representation with dummy coding with N-1 columns. In case of 3 categories(R, G, B), encoding will be R = (1,0),G = (0,1), B = (0,0) | |
| 1:N-1(-1) | Category representation with dummy coding with N-1 columns. In case of 3 categories(R, G, B), encoding will be R = (1,0),G = (0,1), B = (-1,-1) | |
| Variable | Input | The column will be treated as feature during export. |
| Output | The column will be treated as label during export | |
| Ignore | The column will be ignore during export. | |
| Scaling | None | No scaling will be performed during export. |
| MinMax | MinMax normalisation will be performed during export. | |
| Gauss | Gauss standardization will be performed during export. | |
| Missing Value | defines the replacement for the missing value withing the column. There are several options related to numeric and two options (Random and Mode ) for categorical type. | |
| Ignore | In case the missing value whole row will be ommited during export. | |
| Average | Missing value will be replaces with column average value. | |
| Max | Missing value will be replaces with column max value. | |
| Min | Missing value will be replaces with column min value. | |
| Mode | Missing value will be replaces with column mode value. | |
| Random | Usialy good for binary and Categorical columns. Missing value will be replaces with random value. |
- Defines the testing data set size by providing information of row numbers or percent.
- Defines export options,
- Press Export Button.
As can be seen this is straightforward workflow of data preparation.
Besides the general export options which can be achieved by selecting different delimiter options, you can export data set in to CNTK format, which is very handy if you play with CNTK.
After data transformations, the user need to check CNTK format in the export options group box and press Export button in order to get CNTK training and testing files, which can be directly used in the code without any modifications.
Some of examples will be provided in the next blog post.
The project is hosted at GitHub, where the source code can be freely downloaded and used at this location:https://github.com/bhrnjica/MLDataPreparationTool.
In case you want only binaries, the release of version v1.0 is published here: https://github.com/bhrnjica/MLDataPreparationTool/releases/tag/v1.0.