Introduction
In the last years, we have been creating many Machine Learning applications in different business domains. However, all of them share more or less the same requirements and same set of issues. They are all very data-driven and can consume a lot of memory. That means the memory consumption of such an application can bring the host to the limit. Please note, that in this context, the host is the machine that executes the application. These days, the type of host can be very different. For example, you can run the application on a local laptop or server, you can run it in a docker container at the local machine or the cloud-like Azure Container Instances. There are many kinds of such hosts. Another important one in this context is Azure Batch Service.
The idea of this article is to show some differences between different kinds of hosts that are very important when it is required to decide which host to use.
The problem
Assume, there is an application, let’s say ML application that consumes a lot of memory. A lot of memory is a relative term. For example, assume the host has 10GB of available memory for your application. If your application consumes a majority of available memory (i.e. 9GB of 10 GB), we can say it is a lot. That means, to run the application that consumes x-GB of memory it is required x+delta GB of memory, where delta is a relatively small amount, that we just put on top to be sure that the application does not run in out-of-memory.
For example, if your application required 10GB, you can use the host with 11GB, if your application requires 3GB, you can use the host with 4GB etc.
This is what we have learned for decades when creating solutions. But this has changed with cloud and container technologies. All these (new) technologies (ACI, DockerHost, Kubernetes, AppService, Serverless, etc.) create an abstraction layer around your process. They all use different memory management and make lessons learned almost obsolete. That means the amount of required memory is not the same when you host your code at different hosts. And please recall, the required memory in the cloud has a direct impact on the costs of your solution.
Sample Code
I have created the following code, that simulates some job. It runs a loop that on every pass allocates more and more memory in RAM. The method Allocate() receives the argument that specifies the maximum of memory that the code should allocate. That means when started the code is looping up to 120 steps and allocates the maximal specified amount of RAM in GB.
using Microsoft.Extensions.Configuration;
using System.Diagnostics;
namespace Daenet.AzureBestPractices.MyJob
{
private static List<string> list = new List<string>();
public static class Program
{
public static void Main(string[] args)
{
int n = 0;
//
// Fluent API
var builder = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddEnvironmentVariables()
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddCommandLine(args);
for (int i = 0; i < 120; i++)
{
Console.WriteLine($"{n++}");
AllocateMemory(12);
TraceUsage();
Thread.Sleep(1000);
}
}
private static void TraceUsage()
{
Console.WriteLine(
$"PrivateMemorySize64:\t{((double)Process.GetCurrentProcess().
PrivateMemorySize64 /1024 / 1024/1024).ToString("#.##")}");
}
private static void AllocateMemory(int targetSize=2)
{
var proc = Process.GetCurrentProcess();
var sz = ((double)proc.PrivateMemorySize64 / 1024 / 1024 / 1024);
if (sz < targetSize)
{
for (int i = 0; i < 10000000; i++)
{
list.Add("AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA");
}
}
}
}
}
In this example, the maximally allowed memory consumption of the process is 12 GB. To get a feeling of how the memory management works on the Windows machine (in this case my laptop), I have recorded important performance counters for running the code above with the memory limit of 32GB. As you see on the diagram, memory management is a highly dynamic process.
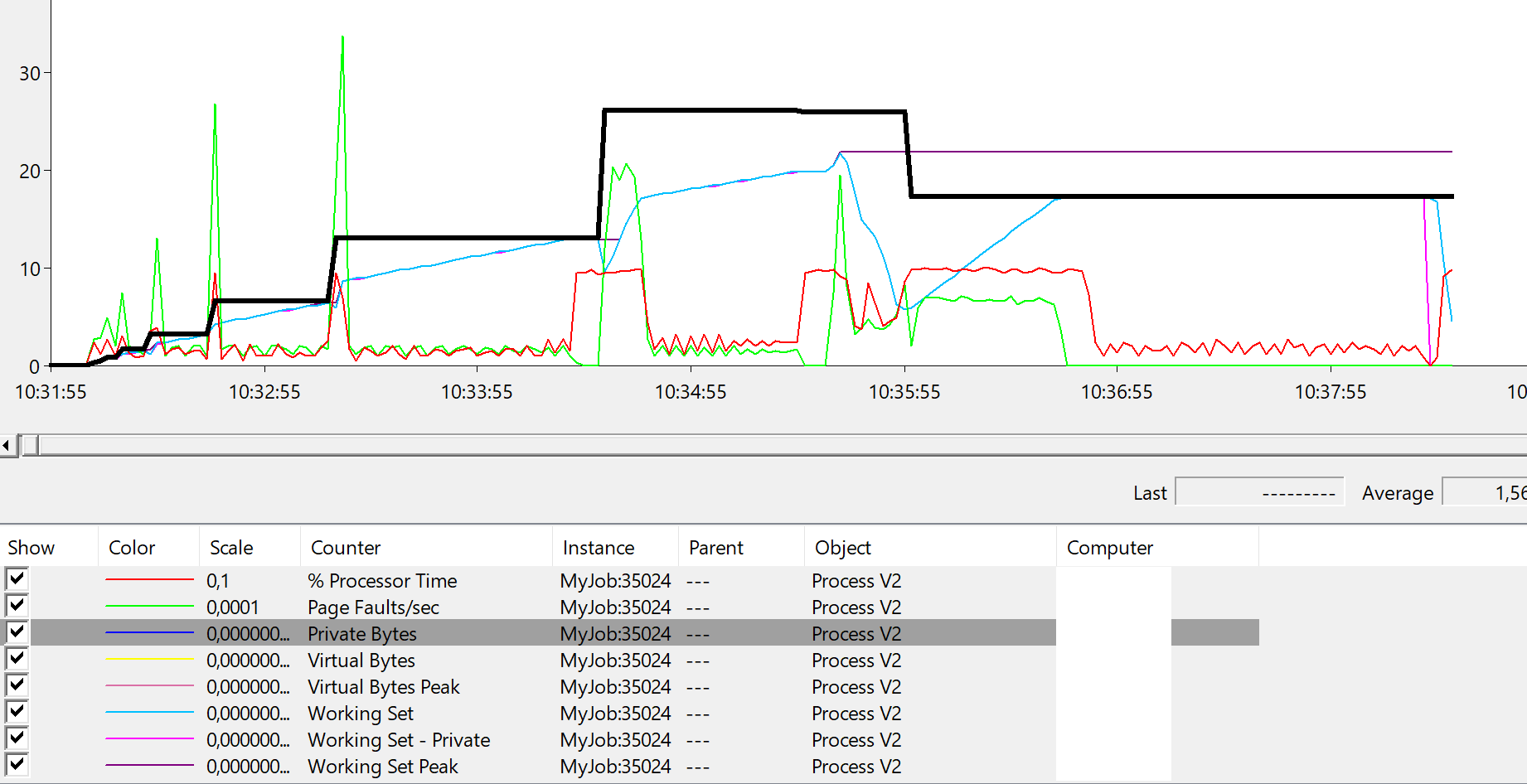
The maximal reached memory was in this case 26GB (bold line). Interestingly my OS reduced the number of private bytes at 10:35 and continued running until stopped with “out of memory” at approx. 10:38:15. The process didn’t reach 32GB, because I had on my machine many other processes that consumed the remaining memory.
One more important finding here. If you take a look on diagram and follow the process CPU, you will notice that it correlates to page faults.Additionally, page faults occur when memory consumption change a lot. This means that optimizing the performance of your code does not depend only on execution of statements in the program code. Optimizing your algorithm to manage a memory better way (avoid memory changes) will help a lot.
Running the code in the Docker container
This code can be run as a docker container at the local machine on for example in Azure Container Instances. Because I set the limit of memory increasing in the example at 12GB, let’s start the container with a lower limit. For example 8GB. I do this, because I want to run in out of memory and want to investigate when that will happen.
docker run -it --rm -m 8g myjob:latest
Please note that available memory is limited to 8GB. When the container is started it will complete in approx. 30 sec. with the error “Out of memory”. Here is the output of the job.
22
PrivateMemorySize64: 4.45
23
PrivateMemorySize64: 4.45
24
PrivateMemorySize64: 4.45
25
PrivateMemorySize64: 4.45
26
Out of memory.
As it can be noticed, the last trace was 4.45GB. The out of memory happened at the next allocation cycle. The output does not show what exact value this was, but it was a bit higher than 4.45GB. It can be noted, that the last written output is approx.. 50% of available RAM (4.45/8).
Let’s execute now the same example in the Azure Container Instances. I have tagged the image and deployed it to Azure Container Registry as vcddevregistry.azurecr.io/myjob:latest.
Then I run it with the following statement:
az container create --resource-group 'RG-VCD-TEST' --name myjob --image vcddevregistry.azurecr.io/myjob:latest --m 8 --cpu 4 --os-type linux --registry-password *** --registry-user vcddevregistry –restart-policy Never
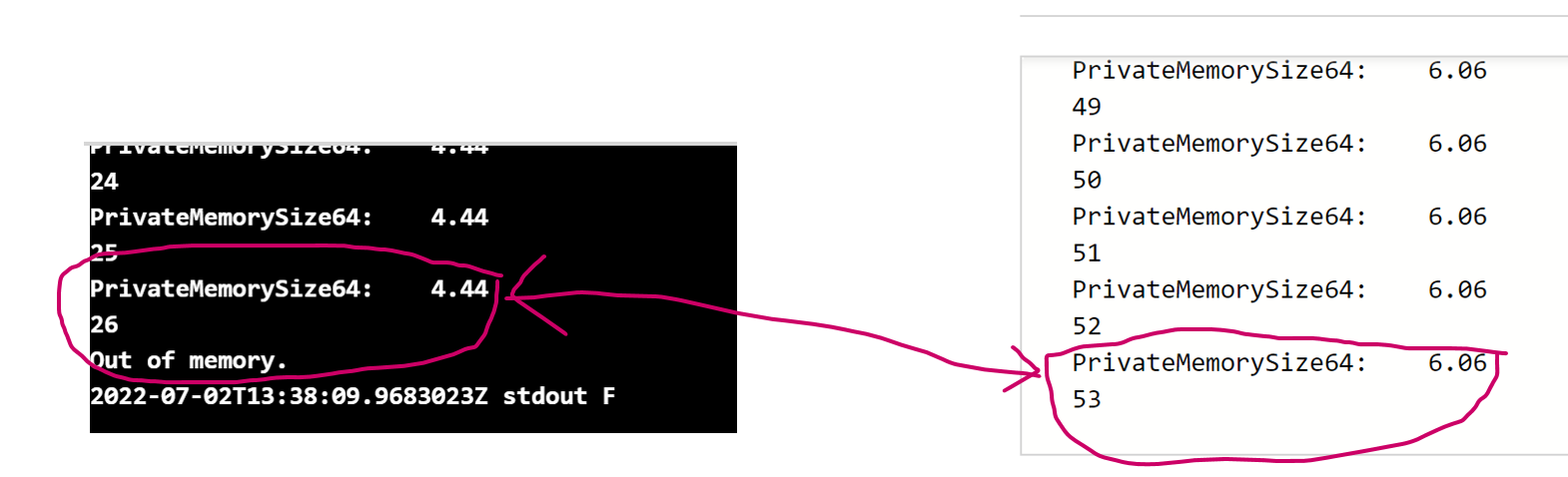
Please notice the restart policy. It is set on Never. This means that the container should not be restarted after it fails with “out of memory”. After 1-2 minutes container will be terminated and you can grab the log output, which indicates nearly the same result. The container crashes in both cases at the same execution step 26 with the same memory consumption.
PrivateMemorySize64: 4.44
24
PrivateMemorySize64: 4.44
25
PrivateMemorySize64: 4.44
26
Out of memory.
The problem with this is that the termination of the job happens at a very low memory threshold in comparison with available memory. Terminating the container at approx. 5GB of 8 GB available memory is too early.
Running the job in the Azure Batch Service
Let’s execute now the same experiment in the Azure Batch Service. After many tries, it can be validated that the same job at the same memory limit executes exactly 53 steps, which is longer execution than in a case of a docker container. The job will be terminated at approx. 6-7 GB by 8FB of available RAM.
The following figure shows the memory consumption of the container in ACI (left) and the Azure Batch Service (right).
Conclusion
Dynamic memory management is a complex task covered by the OS. Results in this article show that OS manages the memory of the process more granularly than the docker host. I do not want to run any philosophical discussion here regarding using VMs vs. Containers in the context of Microservices.
My point here is the following.
1. OS has more granular memory management than “docker hosts”
If you have code that grows in memory as shown in this article, using containers is probably a more expensive option, because you need to allocate almost double memory as required.
2. Some applications cannot run in container
If you have applications that internally control memory management like ML.NET with TensorFlow, they might not be able to execute in a container. Such applications check the available memory and allow use slightly below the threshold. For example, they will allocate for internal use 7.5GB of available 8G.
The consequence of this is that such an application will try to grow up to 7.5GB, but if running in a container, it will crash after probably hours or days of execution long before the 7.5GB will be reached. According to the previously shown result, the application will crash at 4.5-5GB of consumed RAM.
In our projects, we moved such applications from Docker to Azure Batch Service and are happy with the solution.
All related code: ddobric/azure-bestpractices
3. The right host can save costs
Results in this article show that running in a Batch Service (basically VM) requires lower memory, which has a direct impact on costs of the infrastructure of your application in cloud.